.svg)



多くのAIアプリケーションでは、PDF、レポート、申請書、学術論文、法務文書、財務諸表など、長く複雑な文書を検索する必要があります。これらの文書には、テキストだけでなく、表、グラフ、スキャン画像、ページレイアウトといった視覚的要素にも重要な情報が含まれています。
文書AIシステムや検索拡張生成(Retrieval-Augmented Generation、RAG)において、適切な根拠情報を見つけることは、多くの場合、最初かつ最も重要なステップです。誤ったページを取得してしまうと、最終的な回答は不完全になったり、信頼性を欠いたり、十分な根拠に基づかないものになったりする可能性があります。
この課題は、テキストと視覚情報の両方を理解する必要があるマルチモーダルRAGではさらに困難になります。既存のマルチモーダル再ランキング手法は検索品質を向上させることができますが、実運用には処理速度が十分でないことが少なくありません。多数の候補ページを比較する必要がある場合、推論遅延(レイテンシ)がすぐにボトルネックとなります。
ZipRerankは、まさにこの問題を解決するために設計されました。
ZipRerankとは
ZipRerankは、長文書検索のための高速なマルチモーダル再ランキングフレームワークです。AIシステムが最も関連性の高いページをより効率的に特定できるよう支援し、PDF検索、企業向け文書検索、マルチモーダルRAGを実用的なものにします。
ZipRerankは、ユーザーのクエリと文書ページの候補集合を入力として受け取り、より適切に順位付けされた検索結果を高速に生成します。特に以下のような、精度と速度の両方が重要な場面を想定して設計されています。
- 長大なPDFに対する質問応答
- 大規模な文書コレクションを対象とした企業内検索
- 視覚情報が豊富な文書向けの検索拡張生成(RAG)
- テキスト、表、図表、レイアウト情報を活用するマルチモーダルRAGシステム
- 法務、金融、学術、政府関連文書からの証拠情報検索
- 高速かつ根拠に基づいた回答を必要とするAIアシスタント
これらの環境では、再ランキングの高速化によってユーザー体験が向上し、インフラコストが削減され、大規模な文書AIシステムの導入が容易になります。
コアアイデア
ZipRerankは、2つのシンプルなアイデアによって効率性を向上させています。
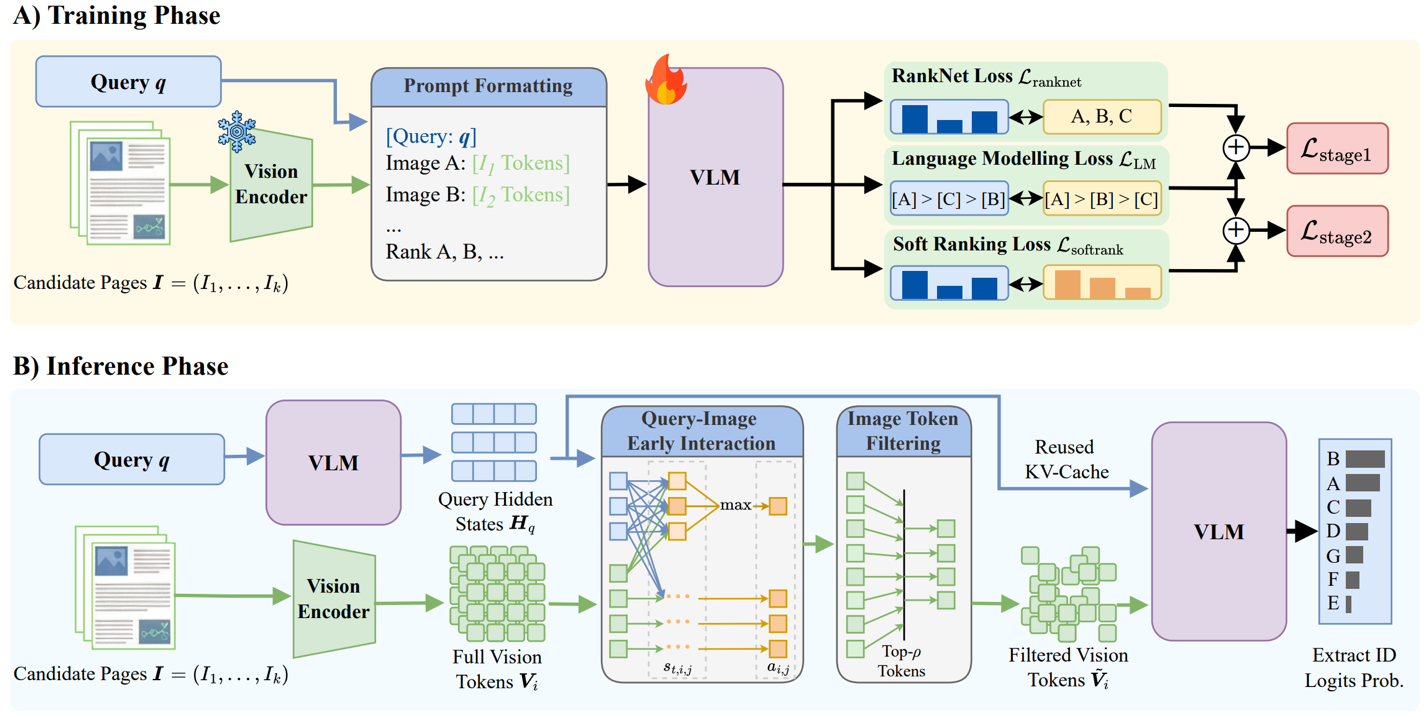
第一に、クエリと最も関連性の高い視覚情報に注目します。候補ページ内のすべての視覚情報を処理するのではなく、重要である可能性が高い部分のみを保持します。
第二に、従来のような逐次的なランキング生成を行いません。代わりに、候補ページを単一の推論パスでスコアリングすることで、再ランキング処理を大幅に高速化します。
これらの工夫により、ZipRerankは高い検索品質を維持しながら、長文書検索やマルチモーダルRAGパイプラインにおけるレイテンシを削減します。
評価結果
私たちは、マルチモーダル文書検索のベンチマークであるMMDocIRおよびViDoReでZipRerankを評価しました。
その結果、ZipRerankは強力な既存のマルチモーダル再ランキング手法と同等、あるいはそれ以上の性能を示しながら、大幅な効率向上を実現しました。MMDocIRでは、大規模言語モデル(LLM)の推論レイテンシを最大で1桁(10倍)削減しました。また、ViDoReの英語サブセットにおいても、視覚情報が豊富な文書検索タスクに対する高い汎化性能を示しています。
これらの結果は、ZipRerankがベンチマーク環境において有効であるだけでなく、企業内検索、PDF質問応答、文書AI、マルチモーダルRAGといったレイテンシが重要な実運用システムにも有望であることを示しています。
公開リソース
再現性の確保と今後の研究支援のため、論文、モデルチェックポイント、および学習コードを公開しています。
- 論文: https://arxiv.org/abs/2605.11864
- モデルチェックポイント: https://huggingface.co/mtri-admin/ZipRerank
- 学習コード: https://github.com/dukesun99/ZipRerank
今後に向けて
AIシステムが長く複雑で視覚情報を多く含む文書を扱う機会が増えるにつれ、高速な検索技術の重要性はさらに高まるでしょう。ZipRerankは、高品質なマルチモーダル再ランキングが必ずしも高いレイテンシを伴う必要はないことを示しています。
再ランキングをより高速かつ実用的にすることで、ZipRerankは文書AI、企業内検索、そしてマルチモーダルRAGの実世界での信頼性ある導入を一歩前進させます。