.svg)



Many AI applications need to search through long and complex documents, including PDFs, reports, forms, academic papers, legal files, and financial statements. These documents often contain important information not only in text, but also in tables, charts, scanned pages, and visual layouts.
For document AI systems and retrieval-augmented generation, or RAG, finding the right evidence is often the first and most important step. If the system retrieves the wrong page, the final answer can be incomplete, unreliable, or poorly grounded.
This challenge is even harder for multimodal RAG, where the system must understand both text and visual information from document pages. Existing multimodal rerankers can improve search quality, but they are often too slow for practical use. When a system needs to compare many candidate pages, latency can quickly become a bottleneck.
That is the problem ZipRerank is designed to solve.
What is ZipRerank
ZipRerank is a fast multimodal reranking framework for long-document retrieval. It helps AI systems identify the most relevant pages more efficiently, making PDF search, enterprise document search, and multimodal RAG more practical for real-world use.
At a high level, ZipRerank takes a user query and a set of candidate document pages, then quickly produces a better-ranked list of results. It is built for scenarios where both accuracy and speed matter, such as:
- answering questions over long PDFs
- enterprise search across large document collections
- retrieval-augmented generation for visually rich documents
- multimodal RAG systems that use text, tables, figures, and layouts
- evidence retrieval from legal, financial, academic, or government documents
- AI assistants that need fast, grounded responses
In these settings, faster reranking can improve user experience, reduce infrastructure cost, and make document AI systems easier to deploy at scale.
The core idea
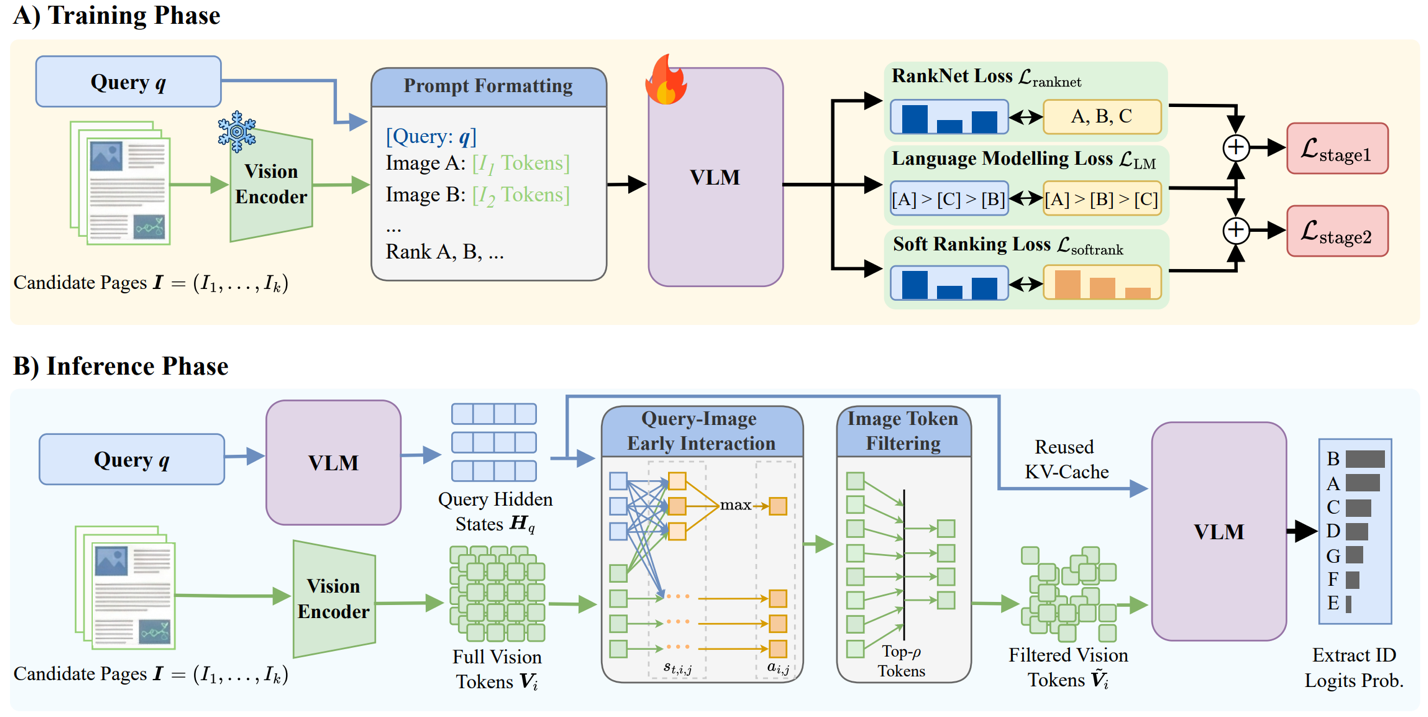
ZipRerank improves efficiency with two simple ideas.
First, it focuses on the visual information most relevant to the query. Instead of processing every visual detail from every candidate page, it keeps the parts that are most likely to matter.
Second, it avoids slow step-by-step ranking generation. Instead, it scores candidate pages in a single pass, making the reranking process much faster.
Together, these ideas help ZipRerank preserve strong retrieval quality while reducing latency for long-document retrieval and multimodal RAG pipelines.
Results
We evaluate ZipRerank on MMDocIR and ViDoRe, two benchmarks for multimodal document retrieval.
Across these evaluations, ZipRerank matches or surpasses strong multimodal rerankers while being substantially more efficient. On MMDocIR, it reduces LLM inference latency by up to an order of magnitude. On the English subset of ViDoRe, ZipRerank also shows strong generalization to visually rich document retrieval scenarios.
These results show that ZipRerank is not only effective in benchmark settings, but also promising for latency-sensitive real-world systems such as enterprise search, PDF question answering, document AI, and multimodal RAG.
Open resources
We are releasing the paper, model checkpoint, and training code to support reproducibility and future research.
- Paper: https://arxiv.org/abs/2605.11864
- Model checkpoint: https://huggingface.co/mtri-admin/ZipRerank
- Training code: https://github.com/dukesun99/ZipRerank
Looking ahead
As AI systems increasingly work with long and visually complex documents, fast retrieval will become more important. ZipRerank shows that high-quality multimodal reranking does not need to come with prohibitive latency.
By making reranking faster and more practical, ZipRerank helps move document AI, enterprise search, and multimodal RAG closer to reliable real-world deployment.