.svg)



Unsupervised video domain adaptation (UVDA) asks us to transfer an action classifier trained on a labeled source domain to an unlabeled target domain. In practice, the shift comes from at least two sources:
- spatial/static differences such as background, lighting, camera style, and scene bias; and
- temporal/dynamic differences such as motion statistics, action tempo, and ordering cues.
Many prior UVDA methods try to address both at once using multiple losses and modules, which increases tuning cost and makes deployment difficult.
MetaTrans revisits a simpler perspective: instead of forcing one representation to handle everything, explicitly separate what is static from what is temporal, then adapt only the part that should transfer.
Introducing MetaTrans
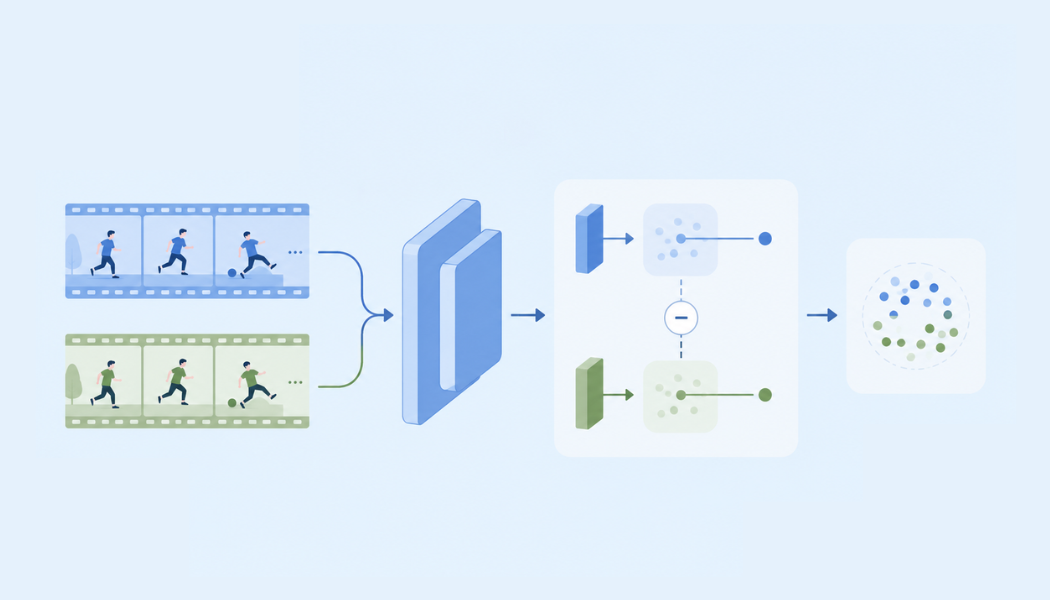
MetaTrans is a two-stream Transformer module that plugs into standard video backbones. Its central operation is static-dynamic subtraction: a permutation-invariant stream estimates clip-level static nuisance factors, and this estimate is subtracted from an order-aware temporal stream to form a residual representation dominated by dynamics.

MetaTrans is designed for UVDA settings where both accuracy and engineering simplicity matter, such as:
- adapting action recognition models across datasets (e.g., UCF-HMDB)
- adapting across environments and camera setups (e.g., EPIC-Kitchens domains)
- training-time efficiency (fewer loss weights and fewer hyperparameter-search attempts)
- robust adaptation when static cues differ strongly between source and target
The core idea: subtract what should not transfer
MetaTrans builds the static/temporal separation into the architecture. The temporal stream M1 receives positional embeddings and produces order-aware tokens; the static stream M2 removes positional embeddings and aggregates over time, making it permutation-invariant by construction. The residual token is formed as F_t = M1(X+P)_t - M2(X). This residual is intended to retain motion/action content while suppressing domain-specific static bias.
Why the static stream is permutation-invariant
A Transformer encoder without positional embeddings is permutation-equivariant with respect to token order: shuffling tokens shuffles the outputs in the same way. After mean pooling, the output becomes permutation-invariant. This matters because a static nuisance factor should not depend on frame order. MetaTrans uses this as a structural constraint instead of adding extra regularizers.
Theory in one line: Proposition 3 to Proposition 2
The analysis connects two steps. Proposition 3 characterizes when the static stream M2 yields a stable estimate of the static component s: under an additive model x_t = s + u_t with mean-zero fluctuations, and under mild calibration and mean-stability conditions, the error ||M2(X) - s|| concentrates and shrinks with clip length T (up to a small calibration floor). Proposition 2 then bounds the post-subtraction domain discrepancy (e.g., Wasserstein distance) of residual tokens F_t by the discrepancy of an ideal residual plus additive terms proportional to the static estimation error on source and target. Together, they explain why subtracting a good static estimate reduces the burden on adversarial alignment.
Results
MetaTrans is evaluated on standard UVDA benchmarks including UCF-HMDB and EPIC-Kitchens domain splits. Across tasks, it matches or outperforms strong UVDA baselines while remaining simpler to tune. The paper also introduces a practical efficiency metric (RGRA, relative gain per running attempt) to quantify how much adaptation gain is achieved per tuning effort, highlighting that simpler objectives can win in real deployment settings.
Looking ahead
MetaTrans shows that UVDA does not always require a long list of auxiliary losses: if the architecture forces the representation to separate static nuisance from dynamics, standard alignment tools become more effective. Future directions include multi-modal inputs (e.g., flow/audio), stronger temporal reasoning modules, and broader evaluation across diverse domain shifts.